
AI Chat Bot エンジン Kagya
Kagyaは、先進的なAIチャットボットエンジンです。Kagyaは、発話内容を分析して、ユーザーやボットの個性に合わせて自動的に応答文を生成することができます。この優れた機能により、Kagyaはお客様のビジネスにとって最適な会話体験を提供します。
3つの特徴
自然言語理解
Kagyaは、話題の継続や相手の発話の一部を利用しての応答が可能です。
チャットボットへのアクセス情報から有用なデータを収集し解析が行えます。
タスク型対話技術
Kagyaは、ユーザーの発話から適切な情報を導き出します。特定のテーマに関して特定の応答を返すルールを定義することができますのでヘルプデスク等のサポート業務も可能に!!
ユーザーに寄り添う
Kagyaは、ユーザーとの会話をよりスムーズにするために、 AI技術を使用した会話を支援する機能を備えています。ユーザーとの会話を安全かつ効率的なものにすることができます。
自然言語理解
Kagyaは、ユーザーとの自然な会話を実現するAIチャットボットエンジンです。入力されたテキストや音声データから、ユーザーの個性や文脈に合わせた最適な応答を生成します。構文解析と意味解析の高度な言語理解技術により、会話の流れを正確に把握し、適切な対話スクリプトを抽出して運用します。また、登録済みの複数の対話ルールから、その場のユーザー発話に最もマッチした応答を構築することが可能です。Kagyaは抜群の会話力で柔軟な対応を実現するチャットボットプラットフォームとして、高い導入効果が期待できます。

タスク型対話技術
ユーザーの目的を達成させるために、達成するための手順を決め、順番に情報を聞き出しながら会話を進めます。
聞き出したい情報はフレームで管理し、フレームの情報が埋まれば外部サーバーに問い合わせます。
話題の継続や相手の発話の一部を利用しての応答が可能です。
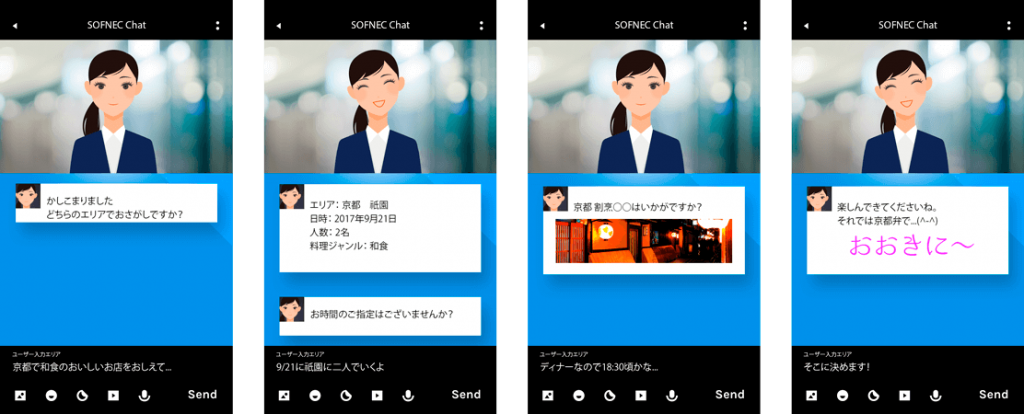
スマートフォンにおいての具体例です。
・様々な出力モダリティ(音声、ボットの表情、画像、フォント)を使って対話します。
・誤った情報を提供しないように、会話の中で得られた情報を表示します。
・入力モダリティは音声だけでなくテキストも可能として、また、タッチ操作で選択も可能とします(複数の情報から選ぶ場合はタッチの方が便利であるため)。
推論技術
AIチャットボットエンジンKagyaは、推論に必要になった事実を問い合わせながら対話形式にて推論を行います。
前向き推論、後向き推論、表形式推論、ファジィ推論、ベイジアンネットワーク推論等を用い与えられた知識を使って推論を行い事実を導き出します。
機能詳細
キーワードマッチングを使っている他社製品に現時点では搭載されていない「様態抽出機能」が実装可能です。
例:~してほしい(願望)~が欲しい(欲求)
発話内容が蓄積した知識データベースに登録されている事実に相当するならば同意する返答を返します。事実に相当しないと判断すれば同意しない返答を返します。
表記ゆれや言い回しの違い等を解析し、同一知識データベースにマッチングさせます。
例:坊ちゃんを書いた人は誰⇒坊ちゃんの作者はすべて、「坊ちゃん」の「作者」は「誰」という質問の知識データベースに落とし込む。
連続した質問などで欠落格、照応詞(先行詞)を補うことにより構文解析を行ないます。
例:エジプトの人口は?の後に インドネシアは?と聞くと
⇒ 「インドネシアの人口は?」とゼロ照応解析して返答
話題継続:「そうそう」「だよね」など同意表現
話題否定:「そうじゃなくて」「そっちの意味じゃなく」など話題ずれ表現
話題確認:「何の話」「何をしゃべってるの」など今の話題確認表現
話題関心:「それって何」「誰それ」など話題にのぼったコンテンツ
データベースには、例えば、呼称がなく入力に「さん」「ちゃん」「選手」「投手」「監督」などが含まれていてもマッチングします。その他、略称などにも対応(エイリアス)します。
例:山田さんの娘は花子だよね
例:山田さんの娘は花子ちゃんだよね
例:新旧字体対応:山縣有朋、佐藤榮作
例:異なる表記対応:3番、三番、3番
システムの利用形態として、APIのみの提供、WebViewおよびiframeでの提供、または、各種既存サービス(LINE,Twitter)上で動作する仕組みを提供致します。
リアルタイムに収集される会話ログを、日付、ユーザー、応答パターン別で検索して表示し不適切な応答を抽出します。
報告用に複数の切り口でどのような会話がされたかを集計し出力します。
AIチャットボットエンジンをご検討中のお客様
※Kagyaはチャットボットエンジンです。Kagyaはソフネックの商標です。
| 機能、利点、長所 | 理由 |
|---|---|
| ルールが少なく、デバッグしやすい | 開発期間が短い、プロトタイプがすぐにでき早く詳細要件が絞り込める |
| 表記ゆれ、シソーラス、類義語 | 多様な言い回しに少数のルールで対応可 |
| 学習、記憶 | 自動的に事実を蓄えることが可、個人嗜好DBなどにも応用可 |
| 推論 | ルールが少なくて済む、条件もれがなく網羅的 |
| マッチング理由が明確 | 説明責任が明確、責任の所在明確、改修時にどのルールを変更すればよいか明確 |
| モジュール構成 | 例えば、応答生成の次に方言モジュールを利用するなどカスタマイズが容易 |
| プログラミングとDBが明確に分離 | 下の参照透過性を参照 |
| 参照透過性、透明性 | 関数(述語)の入力に用いる変数が変更されない、データ構造などに依存しない、副作用がない |
お問い合わせ
AIチャットボットエンジンKagyaのデモや事例が知りたいなどのお問い合わせはこちらからどうぞ。